AI Inference
Oden includes an inference engine based on NVIDIA TensorRT for running neural networks. Requires an NVIDIA GPU (Geforce, Quadro, or Jetson). Networks in ONNX and TRT formats are supported.
The system will automatically convert the ONNX model to a device-optimized TensorRT engine at runtime. This process can take several minutes.
Once loaded, it is possible to retrieve the inference output using the plugin API.
Windows Installation
Usage of the Inference functionality on Windows requires installation of NVIDIA TensorRT. At the time of writing (2023-11-13) the latest version of TensorRT is "8.6 GA" and can be downloaded here: https://developer.nvidia.com/tensorrt (login required). Remember to add the lib directory to PATH, as mentioned in the TensorRT docs.
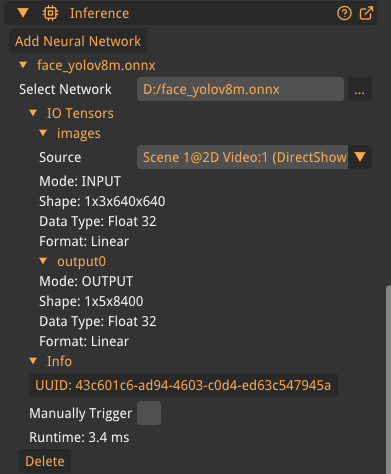
Settings
- Add Neural Network
-
Loads a new neural network (ONNX or TRT)
- IO Tensors
-
Shows information about input/output tensors. Allows the user to select a video stream as input.
- Info
-
Shows the network UUID and runtime duration.
- Manually Trigger
-
Enable manual triggering of the network via the plugin API instead of running continously every frame.